
검색 실력이 부족해서인지 구글링을 해도 딱 이거다하는 howto를 찾기가 힘들어 기록 차 포스팅 합니다.
lambda를 활용할 때 간단한 python 혹은 aws 작업은 handler 내에서 직접처리하도록 구성할 텐데요.
그러다 시간이 지나면 점점 lambda에서 하고싶거나 해야하는 것들이 늘어나게되고 이때 금방 lambda의 제약에 좌절하게 됩니다.
https://docs.aws.amazon.com/ko_kr/lambda/latest/dg/gettingstarted-limits.html
이 제약들 중 가장 아쉬운 것은 python의 풍부한 library를 사용하려면 패키지를 구성 해야하는데 이게 압축해서 50MB를 넘어가면 배포가 불가능하다는 것 입니다. numpy+scipy만 해도 압축 시 100MB정도가 나오거든요. 또 다른 방법으로는 컨테이너 이미지를 만든 후 배포하는 방법이 있는데 이건 lambda의 취지에 맞나?라는 생각이 들기도 하구요. 그래서 전 “lambda에서 glue를 호출”하는 방법으로 이 고민을 해결했습니다.
glue에서는 runtime 시 whl을 통해 필요한 package를 나름 편하게? 설치할 수 있거든요. 또 기본적으로 지원되는 package도 제법 풍부합니다. 이미 설치된 모듈은 여기에서 확인 가능합니다.
https://docs.aws.amazon.com/ko_kr/glue/latest/dg/aws-glue-programming-python-libraries.html
그럼 작업 순서 나갑니다.
1. glue용 코드를 aws console에서 직접작성 하거나 이미 작성한 파일을 업로드 합니다.
2. 설정 탭에서 glue 작업명을 입력해주시고 코드에 s3 등의 조작이 있다면 IAM에서 이에 필요한 권한을 추가 부여해 줍니다. 저는 s3에 대한 조작이 있어서 아래와 같은 권한을 추가했습니다. (안하면 403에러를 자주 볼겁니다. 🙂
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::your_bucket/*"
}
]
}3. 필요한 library의 whl를 다운받아 s3에 upload 합니다. (pip wheel -r package명[혹은 목록 파일])
4. Advanced properties > Libraries > Python library path에 3에서 지정한 whl 경로를 입력합니다.

여기까지 왔으면 glue 작업은 완료되었습니다. runjob 해보세요!
이제 lambda 작업을 구성 해보겠습니다.
5. 스크립트 작성 (저는 python으로 했습니다.)
import json
import os
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
import boto3
glueJobName = "airguy_glue_helloworld"
# Define Lambda function
def lambda_handler(event, context):
client = boto3.client('glue')
logger.info('## INITIATED BY EVENT: ')
response = client.start_job_run(JobName = glueJobName,
Arguments = {
'--param1': "1",
'--param2': "22",
'--start_dt': "2022-01-01",
'--end_dt': "2022-05-10" })
logger.info('## start glue job: ' + glueJobName)
logger.info('## runid: ' + response['JobRunId'])
return responsestart_job_run의 jobName에 2에서 설정한 glue 작업명을 입력해 주셔야 합니다.
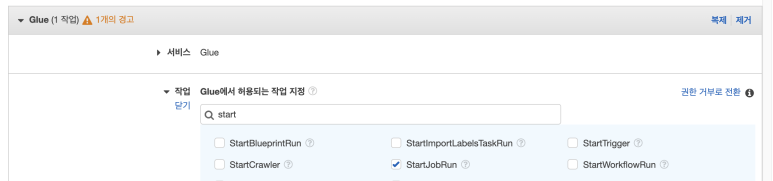
6. lambda에서 start_job_run 코드가 이상없이 구동되도록 glue:StartJobRun 권한을 IAM 통해서 추가합니다.
lambda는 glue를 호출한 후 바로 종료되고 glue가 실행 중임을 console 혹은 cloud watch를 통해 확인 할 수 있습니다.
5~6시간 삽질한 것 같은데 글로 쓰니 얼마 안되네요 ^^;;
이 삽질을 왜 했냐 궁금하실 듯한데요.
저는 lambda가 특정 트리거로 발현되었을 때
- Aurora DB에서 일부파일을 dump 떠서 s3에 올린 후 athena table을 생성한 다음
- pyathena를 통해 big-query ETL을 수행하고 그룹핑하여 작아진 결과물을 pandas dataframe으로 만들어
- 이를 학습데이터로 활용하여 각종 ML/AI코드를 구동, 결과물을 다시 Aurora DB에 insert 하고
- 마지막으로 dataframe을 만든 김에 이를 이용해 matplotlib chart를 만들어 status를 시각화하여 배포함
을 수행하도록 구성해 봤습니다.
Aurora DB에서만 이런 요건을 처리하다보면 특정시점에 부하가 집중되다보니 iops조정, 샤딩, 스케일 업/아웃 등 스펙을 올리는 작업을 하거나 혹은 redshift, HADOOP 등으로 아예 datalake 혹은 dw를 구축하는 것이 일반적인 접근일텐데요. 위의 예시처럼 각 요건을 독립적으로 나누어 필요한 data를 DB외부로 deploy한 후 처리하게 하여 DB에 집중되던 부하를 제거하는 micro-service를 lambda와 glue를 통해 단시간 내에 구현할 수 있었습니다. 또 만들다보니 glue 작업은 조금만 신경써서 구현하면 꼭 glue가 아니더라도 on-premise나 EMR 등에서도 바로 구동 가능하게도 만들 수 있다보니 작업이 더 비대해졌을 때에 각 작업을 datalake로 포팅하는 과정 또한 쉬워지는 장점도 있을 것 같습니다.
처음에는 어떻게 설정하느냐를 쓰다 결론이 좀 이상하게 된 것 같은데요. 이것도 나름 유용한 정보가 될 듯하여 그냥 남겨둬볼까 합니다.
그럼 긴 글 읽어주셔서 감사합니다.
