보통 SPARK와 HADOOP은 한 몸처럼 붙어 다니는데요.
SPARK를 구동하기 위해서는
1. 소스테이터를 읽어드리기 위한 파일시스템
2. 결과를 쓰기위한 파일시스템
3. 분산작업 시 생성되는 driver, executor(s)의 리소스 컨트롤러
가 필요합니다.
HADOOP에서는 HDFS가 1, 2을 YARN에서 3을 해소해 주기 때문에 아주 궁합이 좋아 한 몸처럼 사용하는 경우가 대부분 입니다.
그렇다보니 SPARK를 사용하려면 HADOOP을 사용해야하는 것으로 오해하는 경우가 많아
이번 글에서는
STANDALONE 모드로 HADOOP 없이 SPARK 클러스터를 구성
하는 방법을 설명드려볼까 합니다.
테스트 용도로 장비 2대를 준비해 봤구요… (개인용도로 사용하고 있는 m1 맥북에어, m1 미니)
작업 순서는 다음과 같습니다.
주의: python, java 등은 이미 설치되어 있는 것을 전제하고 설명 드리고 있습니다.
0. SPARK 다운로드
원하시는 버전을 두 장비에 다운로드 하신 후 압축을 풀어줍니다.
저는 편의상 여기에 심볼릭링크를 추가하여 필요 시 마다 버전을 변경하며 사용하고 있습니다.
wget http://apache.mirror.cdnetworks.com/spark/spark-{버전에맞게}/spark-{버전에맞게}-bin-hadoop2.7.tgz
tar -xvf spark-~~~~~.tgz
### ln -s spark spark-3.1.2-bin-hadoop21. hosts 설정 (airguy.air, airguy.mini 두 곳에…)
/etc/hosts의 파일을 수정하여 각 장비의 호스트명을 기입합니다.
127.0.0.1 localhost
255.255.255.255 broadcasthost
::1 localhost
192.168.0.48 airguy.air
192.168.0.89 airguy.mini2. spark-env.sh 설정 (airguy.air, airguy.mini 두 곳에…)
${SPARK_HOME}/conf에 spark-env.sh.template를 spark-env.sh로 복사해서 사용하시면 됩니다.
export SPARK_MASTER_HOST=airguy_mini
export SPARK_WORKER_INSTANCES=1 #
export SPARK_WORKER_CORES=4 #한 물리장비에서 NIO, Disk I/O 때문에 4코어정도가 적당하더라.
export SPARK_WORKER_MEMORY=8g #워커에게 할당될 메모리 자원, 이설정이면 4개의 core가 8G를 나눠씀
export SPARK_LOCAL_IP={노드장비의 IP} #이것을 설정하지 않으면 WORKER가 127.0.0.1로 잡혀 remote node가 작동되지 않는다.
export SPARK_LOCAL_DIRS="/Users/airguy_mini/dev_env/spark/scratch_disk" #데이터 저장소 지정작업 중 임시로 디스크를 사용할 경우를 대비하여 SPARK_LOCAL_DIRS를 설정했구요.
가장 중요한 SPARK_LOCAL_IP에는 해당 클러스터의 IP를 명시해 주셔야 합니다.
이 속성이 설정되지 않으면 WORKER에서 remote node가 보이긴 하나 localhost로 나타나며 application에서 core를 할당받지 못하여 계속 작업이 실패되는 모습을 보게 될 것 입니다. 🙂
[필수아님] 3. spark-default.sh 설정 (airguy.air, airguy.mini 두 곳에…)
이 설정은 실제 submit되는 작업에서도 구성할 수 있기 때문에 필수는 아니지만 코드 무결성 등의 편의를 위해 설정을 추천드립니다.
spark.master spark://airguy.mini:7077
spark.eventLog.enabled true
spark.eventLog.dir /Users/airguy_mini/dev_env/spark/logs
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.executor.logs.rolling.maxRetainedFiles 30
spark.executor.logs.rolling.strategy time
spark.executor.logs.rolling.time.interval dailyspark master가 구동되면 master_host:7077로 구동되기 때문에 이를 미리 설정해 뒀습니다.
밑에서 코드로도 설정해 보겠습니다.
이외에 로그가 쌓이는 경로(spark.eventLog.dir)도 제 PC에 맞춰 설정했습니다.
4. MASTER 및 WORKER의 실행
4.1 마스터장비(airguy.mini)의 ${SPARK_HOME}/sbin에서 아래와 같이 master를 실행합니다.
start-master.sh4.2 마스터장비(airguy.mini)와 노드장비(airguy.air)의 ${SPARK_HOME}/sbin에서 아래와 같이 worker를 실행합니다.
start-worker.sh spark://${SPARK_MASTER_HOST}:7077
이후 airguy.mini:7077로 접속하면 다음과 같은 화면을 보실 수 있습니다.
192.168.0.48, 89 2개의 장비에서 worker가 구동되고 있음을 확인하실 수 있습니다.
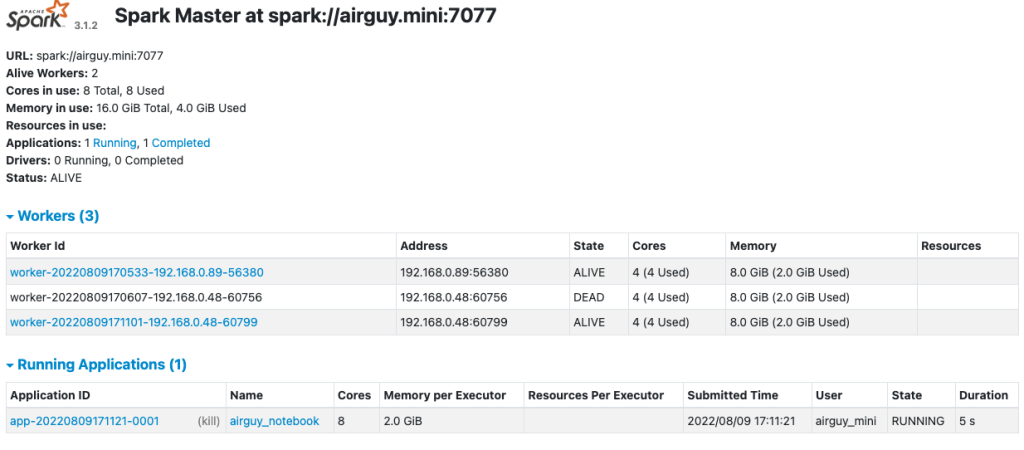
저는 각 PC의 계정이 틀려 설정하지 않았지만 계정이 같은 환경이라면 authorized_keys를 설정하여 마스터 노드에서 start-all.sh, start-workers.sh등으로 리모트 장비까지 일괄명령을 내릴 수 있습니다.
5. 작업 실행
S3에 있는 데이터를 읽어올 수 있도록 설정하여 작업해 보겠습니다.
import pyspark
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from pyspark.sql.types import *
from pyspark.sql import Row
ACCESS_KEY = '************'
SECRET_KEY = '*************************'
S3_REGION = 's3.eu-west-2.amazonaws.com'
conf = pyspark.SparkConf().setAppName("airguy_notebook")
conf.setMaster("spark://airguy.mini:7077")
#conf.set("spark.driver.memory", "20g")
conf.set("spark.executor.memory", "2g") #이렇게하면 executor당 2g씩 할당가능
conf.set("spark.hadoop.fs.s3a.access.key", ACCESS_KEY)
conf.set("spark.hadoop.fs.s3a.secret.key", SECRET_KEY)
conf.set("spark.hadoop.fs.s3a.endpoint", S3_REGION)
spark = SparkSession.builder.config(conf=conf).getOrCreate()
spark.sparkContext.setSystemProperty("com.amazonaws.services.s3.enableV4", "true")
s3_df = spark.read.parquet("s3a://airguy/test_data/dt=202207*/*.parquet")
s3_df.count()작업이 수행되면 UI에서 작업이 구동되는 이력과 이때 출력되는 로그를 확인 가능합니다.
한장비에 4core 씩 설정했는데 8core 모두 열심히 일 잘하고 있네요….
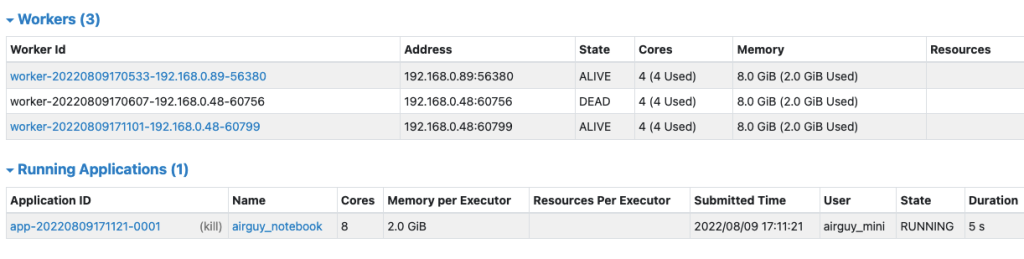
S3를 입력데이터 및 출력데이터의 저장소로 설정하고 SPARK 클러스터 만으로만 구성해봤습니다.
SPARK가 컨테이너로 구성된다면 무겁고 비싸고 운영하기 힘든 HADOOP 클러스터는 필요 없을 수도 있겠습니다.
Athena 등을 통해 SPARK로 유입되는 데이터를 좀 더 줄인다면 더 효과적일 것이구요.
빅데이터를 처리하기 위해 꼭 하둡기반 데이터레이크가 필요한가?
를 생각해볼 수 있는 재밌는 실험이었어서 포스팅 해봤습니다.
긴 글 읽어주셔서 감사합니다.
